Overview
Role: Solo Programmer/3D Artist
Tools Used: Unity3D, Blender, Adobe Photoshop, Meshlab, Docker
Collaborators: Professor Rita Singh, Mahmoud Al Ismail
Intent
CMU Language Technology Institute professor Rita Singh works on voice profiling research, where she analyzes aspects of a person's vocal frequencies to determine physical characteristics such as age, height, weight, gender, and race. Part of her research includes estimating the structure of someone's face based on their voice.
She was asked to present this research at the World Economic Forum conference, the 2018 Annual Meeting of the New Champions. Although the research is not yet complete, the demo serves as an interactive proof of concept for voice to face technology (and how it could be extended to generate entire bodies and environments).
Process
Voice Recording Controls
The main challenge of creating the demo in general was designing an interface that would be intuitive to people who have never used VR before, as this would be the case with many of the guests at the conference. Also, many of the conference participants did not speak English, or spoke it as a second language, so this influenced my decision to make the majority of the interfaces operate using universally-recognized symbols or pictures.
For example, the voice recording controls of the demo (below) use the Record, Play, and Stop icons on the corresponding buttons. This turned out to be effective, as almost all of the guests in the demo immediately understood whenever I would instruct them to begin by recording their voice on the panel.
The demo uses the Oculus Rift's internal microphone to record up to 60 seconds of audio while the participant reads the passage that appears on the screen aloud. Once they are finished, the demo sends the recorded audio to a back end server that analyzes the voice and returns a point cloud of the participant's face.

The Recording Controls in the voice profiling demo
Data Collection Interface
The demo also includes functionality for saving participants' physical data along with their voices, but this feature was disabled in the WEF build due to their privacy restrictions on saving participant information.
Using a separate machine from the voice recording controls, participants input their race, height, weight, age, and gender. Once the participant records their voice, the data inputted by the participant is sent along with the voice recording to the back end server and can then be included in new datasets used to improve the voice analysis algorithms.
In addition to the virtual interface for the participants to use, I also created an iPad application that communicates with the VR demo and allows me (or whoever is operating the VR demo) to input user data independently. The iPad application and the VR demo communicate using the Unity Networking module. On startup, the VR demo act as a server and generate an IP address (seen in the lower left corner of the video above) for the iPad to connect to.
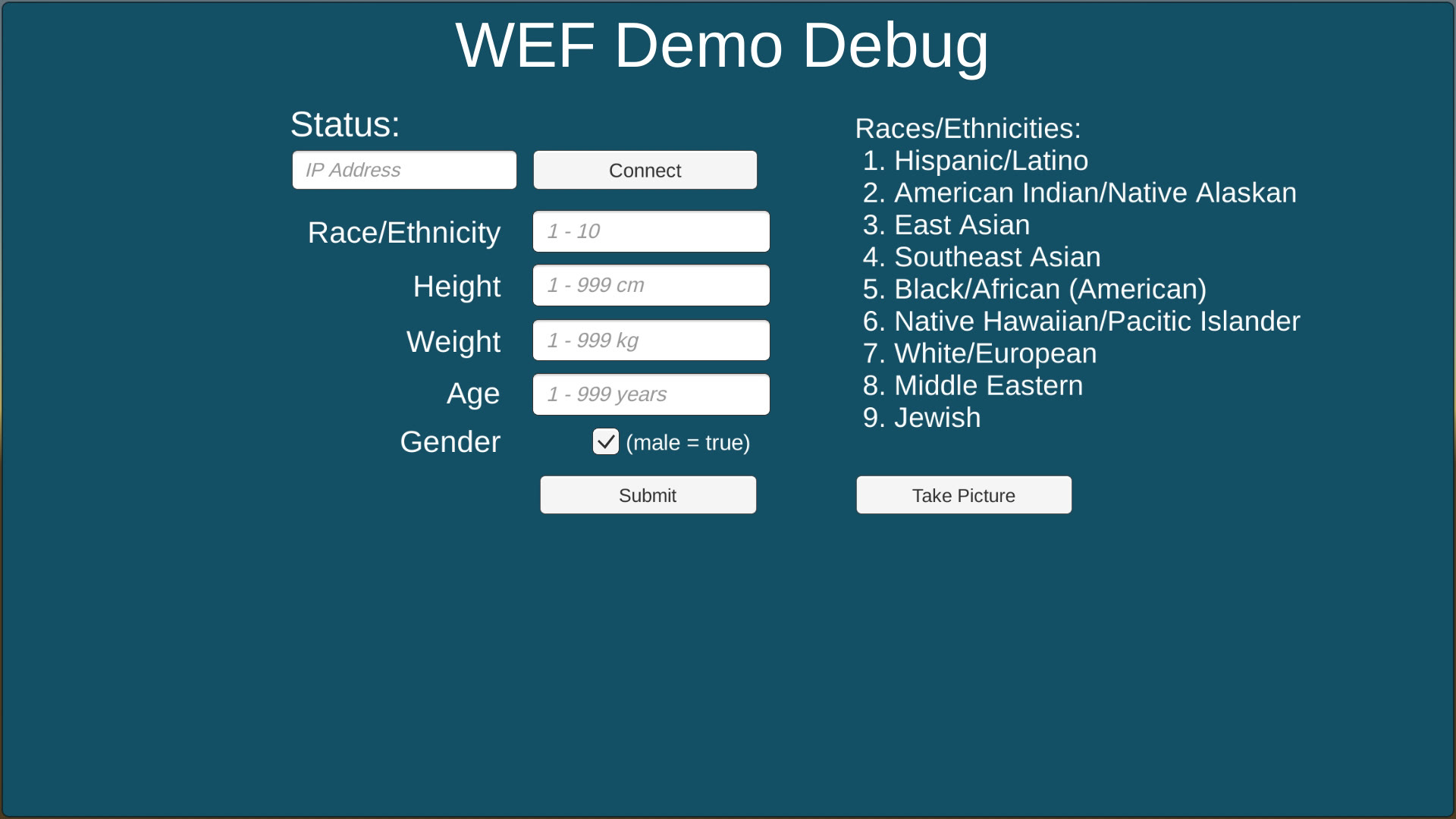
A screenshot of the iPad interface used for data collection
Product
The final product was demonstrated as part of the Carnegie Mellon's Digital Traces booth at the World Economic Forum's 2018 Annual Meeting of the New Champions held in Tianjin, China. The AMNC is a summit specifically focused on scientific and technological innovation and how it can affect society in a global context. This year, the conference hosted over 2000 participants from around the globe, of which over 900 experienced the demo. I also demonstrated the VR experience on several live Chinese television news networks.




Conference participants trying out the VR demo